
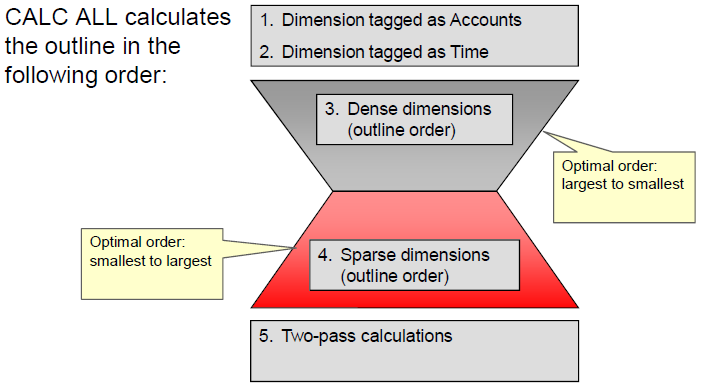
- Hour Glass Model: Design The Outline in Hour Glass Model
- Defragmentation: Fragmentation can be caused any of the below reasons,
- Frequent data loads
- Frequent data retrieval &
- Calculations.
We can check whether the cube is fragmented or not by seeing its Average Clustering Ratio in the properties Tab. The Optimum clustering value is 1. If the average clustering ratio is less than 1, then the cube is fragmented which degrades the performance of the cube.
Defragmentation can be done by,
- Exporting Data of the application into a text file, then clearing the data and reloading the data using text file without using Rules file(Exported data do not need rules file while importing the data).
- Using MAXL Command: Alter Database App name .DB name Force Restructure;
- Add and Delete One Dummy Member in the Dense Dimension to force a full restructure.
- Database Restructuring: There are three types of restructure i.e.,
- Outline Restructure: When we rename any member or add Alias to any member or member formula changes then outline Restructure would happen
- Sparse restructure: when we moved, deleted, or added a member to a sparse dimension then sparse restructure would happen.
- Dense/Full Restructure: If we want to moved, delete and add a member to a dense dimension then dense Restructure would happen
- Compression Techniques: When Essbase stores blocks to disk, it can compress the data blocks using one of the following compression methods, this is based on the type of data that is being loaded into the Essbase database.
- No Compression: It is what it says, no compression is occurring on the database.
- ZLib Compression: This is a good choice if your database has very sparse data.
- Bitmap compression: This is the default compression type and is good for non-repeating data.
- RLE (Run Length Encoding) compression: This type of compression is best used for data with many zeroes or repeating values.
In most of all cases Bitmap is always the best choice to give your database the best combination of great performance and small data files. On the other hand much depends on the configuration of the data that is being placed into the database. The best way to determine the best method of compression is to attempt each type and evaluate the results.
- Cache Settings
- Intelligent Calculation:
When a full database calculation is performed, Essbase marks the data blocks that were calculated. Subsequently whenever data is loaded or subset of data is loaded, we can calculate the changed data blocks and their ancestors.
Note: By default intelligent calculation is enabled. We can change the default settings in essbase.cfg file or by using SET UPDATECALC OFF (Script by script basis).
Intelligent calculation is based on data-block marking. When intelligent calculation is enabled, the following occurs:
- During normal processes, within the index file, blocks are marked clean (blocks that do not require calculation) or dirty (blocks that require calculation).
- During calculation, Essbase looks for only dirty data blocks.
- Data Load Optimization: Data load optimization can be achieved by the following.
- Always load the data from the Server than file system.
- The data should be at last after the combinations.
- Should use #MI instead of ‘0’s. If we use ‘0’ uses 8 bytes of memory for each cell.
- Restrict max Decimal Points to ‘3’ –à 1.234
- Always Pre-Aggregate data before loading data in to Database
- Parallel Data Load: DL Threads write (4/8): Used for Parallel Data loads. Loads 4 records at a time for 32-Bit system and 8 records for 64-Bit system. By default Essbase Loads data Record – by – Record which would consume more time resulting in consuming huge time for data load.
- Uncommitted Access: Under uncommitted access, Essbase locks blocks for write access until Essbase finishes updating the block. Under committed access, Essbase holds locks until a transaction completes. With uncommitted access, blocks are released more frequently than with committed access. The Essbase performance is better if we set uncommitted access. Besides, parallel calculation only works with uncommitted access.
Things to Remember:
Data Block: Essbase creates a data block for each unique combination of sparse dimension members (providing that at least one data value exists for the combination).Each data block contains all the dense dimension member values for its unique combination of sparse dimension members.
Potential number of data blocks: total number of stored members in Sparse Dimension 1* total number of stored members in Sparse Dimension 2.
Ex: - If Product Dimension has 25 stored members & Market Dimension has 19 stored members, then 19* 25 gives potential number of blocks.
Number of existing data blocks = Estimated density * potential number of blocks
Different levels of sparsity or Estimated density i.e. extremely sparse (5 % of potential data cells exist), Sparse (15 % of potential data cells exist) & Dense (50 % of potential data cells exist)
Number of data Cells: Total number of members in Dense1 * Total number of members in Dense2
Block Size: Total number of members in Dense1 * Total number of members in Dense2 * 8 kb
No comments:
Post a Comment