
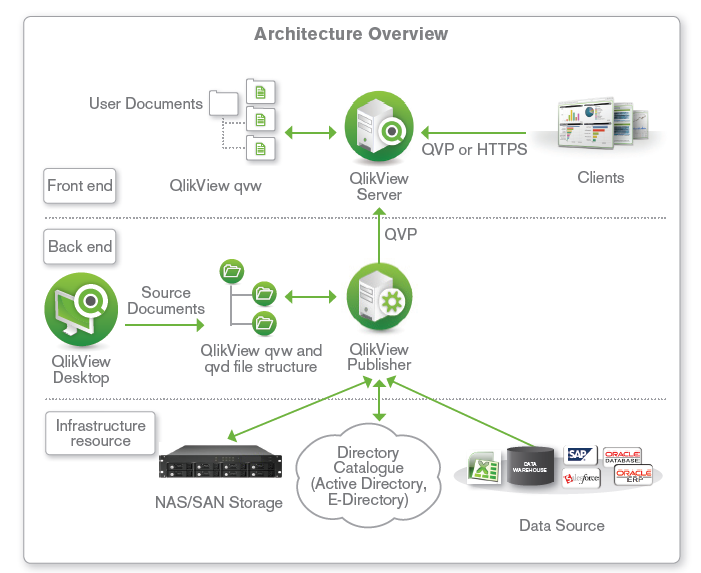
(FIGURE 1)
- QlikView deployments have Three main infrastructure components:
1) QlikView Developer
2) QlikView Server (QVS)
3) QlikView Publisher.
- QlikView Developer is a Windows-based desktop tool that is used by designers and developers to create
1) A data extract and transformation model
2) The graphical user interface (or presentation layer).
- QlikView Server (QVS) handles the communication between clients and the QlikView applications. It loads QlikView applications into memory and calculates and presents user selections in real time.
- QlikView Publisher loads data from different data sources (oledb/odbc, xml, and xls), reduces the QlikView application and distributes to a QVS.
Back End (Including Infrastructure Resources):
This is where QlikView source documents, created using the QlikView Developer, reside. These source files contain either
a) Scripts within QVW files to extract data from the various data sources (e.g. data warehouses, Excel files, SAP, Salesforce.com) or
b) The actual binary data extracts themselves within QVD files.
The main QlikView product component that resides on the Back End is the QlikView Publisher: the Publisher is responsible for data loads and distribution.
Within the Back End, the Windows file system is always in charge of authorization (i.e. QlikView is not responsible for access privileges). The Back End depicted in figure 1 is suitable for both development, testing and deployment environments.
Front End:
The Front End is where end users interact with the documents and data that they are authorized to see via the QlikView Server. It contains the QlikView user documents that have been created via the QlikView Publisher on the back end.
The file types seen on the Front End are QVW, .meta and .shared documents. All communication between the client and server occurs here and is handled either via HTTPS (in the case of the AJAX client) or via the QlikView proprietary QVP protocol (in the case of the plugin or Windows client). Within the Front End, the QVS is responsible for client security
Associative In-Memory Technology:
QlikView uses an associative in-memory technology to allow users to analyse and process data very quickly. Unique entries are only stored once in-memory: everything else are pointers to the parent data. That’s why QlikView is faster and stores more data in memory than traditional cubes. Memory and CPU sizing is very important for QlikView, end user experience is directly connected to the hardware QlikView is running on. The main performance factors are data model complexity, amount of unique data, UI design and concurrent users
MEMORY: Main memory RAM is the primary storage location for all data to be analyzed by QlikView. QlikView uses RAM to store the unaggregated dataset to be analyzed as well as the aggregated data and session state for each user viewing a QlikView document.
QlikView is a snapshot based technology. The snapshot is refreshed through a process known as reloading a QlikView document. When a QlikView document is reloaded QlikView will establish connectivity to the datasource (or datasources) to be analyzed and extract all the unaggregated granular data from the data source and then compresses this data.
The unaggregated compressed dataset is then saved to disk for persistent storage as a .QVW file. At the beginning of an analytic session QlikView will load a QlikView document from persistent disk based storage (i.e. a QVW file from hard disk) and place the entire dataset into RAM.
During an analytic session QlikView will not make a call out to the database or access any other disk based data repository: It will only rely on the dataset present in RAM. This is what gives QlikView the unlimited flexibility and near instantaneous response times (all data is aggregated in RAM). But, of course, to take advantage of the benefits QlikView provides, all data to be analyzed must fit in RAM.
IMPACT OF TOO LITTLE RAM AVAILABLE: Like all Microsoft Windows applications, QlikView is dependent on Windows to allocate RAM for QlikView to use. QlikView Server will attempt to reserve RAM when it starts based on the “Working Set Limits” set in the QlikView Server Management Console. If at any time RAM becomes scarce, Windows may, at its discretion, swap some of QlikView’s memory from physical RAM to Virtual Memory (i.e. use the hard disk based cache to in place of RAM). When QlikView is allocated Virtual Memory it may be orders of magnitude slower than when using 100% RAM. This is always an undesirable condition in QlikView and will provide a poorer experience for the end users and may be perceived as an error condition by end users.
QlikView Publisher:
CPU: QlikView Publisher is a database load engine. Every database connection will creates one thread, meaning that for every data load one core will be utilized almost 100%. Therefore, the maximum number of simultaneous database loads is usually the same as number of processor cores available. A comparison of how Publisher and the QVS uses CPU resources highlights the best practice of not having both Publisher and QVS on the same server.
HARD DRIVE: In a well-designed system, Publisher will run specially crafted QlikView applications whose only purpose is to create QlikView data files (qvd), QlikView data marts (qvw files with no graphical interface) and/or reduced QlikView end-user documents (qvw files). This creates historical data repositories that QlikView end user applications will load from (a data cache set). The advantage of this is that it reduces database communication and shortens the reload time. The drawback is the disk space needed to store these source files. The amount of disk size needed depends on data amount loaded from the source databases. It is recommended to use a raid 5 or SAN/NAS drive with at least 150GB of space.
MEMORY: Because the Publisher is a database reload engine and file distribution service rather than an analytics engine, it is not as memory intensive as the QVS. Therefore, memory considerations are typically not a key factor in determining server sizing for Publisher instances.
Thx For Your Tutorials and Information On Qlikview Online Training it will be most usefull for Beginers, Who are learning Qlikview Through Online Training and Web
ReplyDeletesalesforce training
ReplyDeletehadoop training
Data Science training
linux training
mulesoft training
web methods training
business analyst online training
oracle adf online training